Anthropic’s Approach to Effective Context Engineering for AI Agents
Effective Agent-Building Methods Used by Anthropic
Effective context engineering for AI Agents: Claude (Eng)
0. Introduction
To build effective AI agents, one needs to go beyond prompt engineering and understand and apply the concept of context engineering. This piece reorganizes information from a practical perspective focused not on the inner workings of LLMs, but on the question “How do we build effective agents?” We aim to understand what Anthropic defines as context engineering and how they structure prompts and agents efficiently.
This article is a refined, summarized version of the original in the author’s own language. Refer to the original for more detail.
1. Background
Context in LLMs refers to the set of tokens available during generation. The core challenge of context engineering is to maximize the utility of this limited context to reliably guide model behavior. Building effective agents requires understanding and shaping the LLM’s holistic state at any given moment. This post introduces key principles and a mental model for creating more controllable and capable agents through context engineering.
2. Context Engineering vs. Prompt Engineering
Anthropic views context engineering as the progression of prompt engineering. Prompt engineering refers to how to write and structure LLM instructions for optimal results. Context engineering refers to a set of strategies for selecting and maintaining the optimal set of tokens (information) during LLM inference, which can include information beyond the prompt.
In the early days of LLM engineering, aside from chat, most uses centered on one-shot classification and text generation. Because of this, “how to craft the prompt” was the most important part of AI engineering. But as we moved toward systems where multiple agents work together, it became necessary to manage the overall context state, including system instructions, tools, MCP, external data, message history, and more.
Agents running in loops generate more data that could be relevant at each successive reasoning step, and this information must be periodically distilled. Context engineering is the technique of selecting what to include within a limited context window.
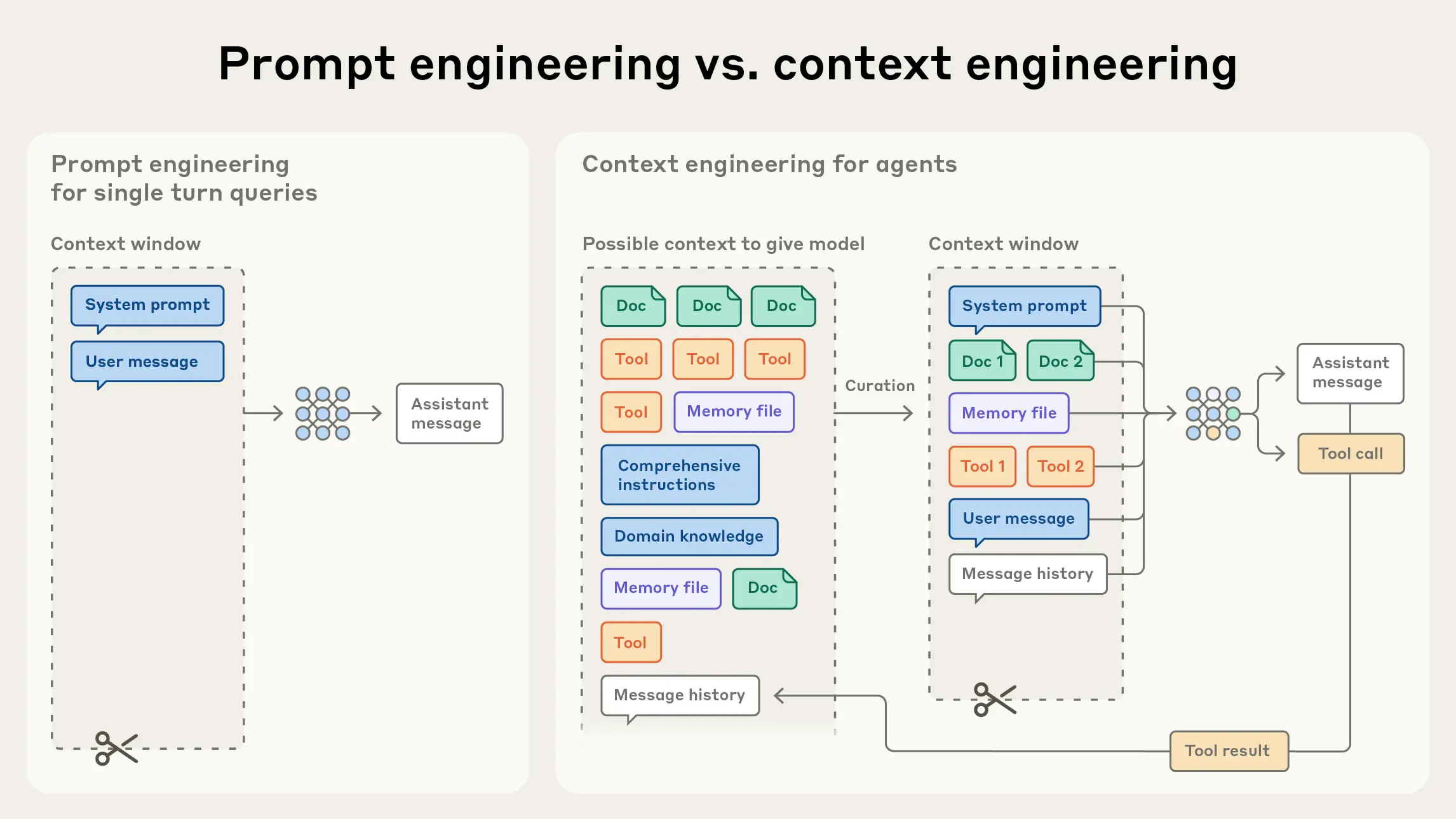
In contrast to the discrete task of writing a prompt, context engineering is iterative and the curation phase happens each time we decide what to pass to the model.
3. Why context engineering is important to building capable agents
Despite their speed and ability to process large volumes of data, LLMs can lose the thread or get confused at certain points (context rot). Put differently, as the token count in the context window increases, models become worse at retrieving information from that context.
Because this phenomenon occurs across all models, context should be treated as a finite resource. That is, when LLMs analyze large volumes of context, they have an “attention budget.” Each new token depletes this budget, so the tokens available to the LLM must be selected carefully.
Because an attention budget exists, context engineering is important for building effective agents.
4. The Anatomy of Effective Context
Given that LLMs operate under limited attentional resources, effective context engineering is about finding and using the minimal set of high-signal tokens that best guide the model to the desired outcome. The following sections explain what this principle means across different components of context.
System prompts must be truly clear, written in direct language at an appropriately abstract level, and kept simple for the agent. The appropriate level of abstraction is the sweet spot between two common failure modes.
If you hardcode complex, brittle logic into the prompt, you increase fragility and maintenance complexity. At the opposite extreme, you write prompts that are overly abstract and vague. In that case, the LLM lacks concrete cues for the expected outcomes, or the prompt mistakenly assumes the model already shares the same background knowledge.
The right prompt lies in the middle ground between these two extremes. It should be specific enough to explain how to act effectively, while still flexible enough to provide strong empirical heuristics even if not the “one right answer.”
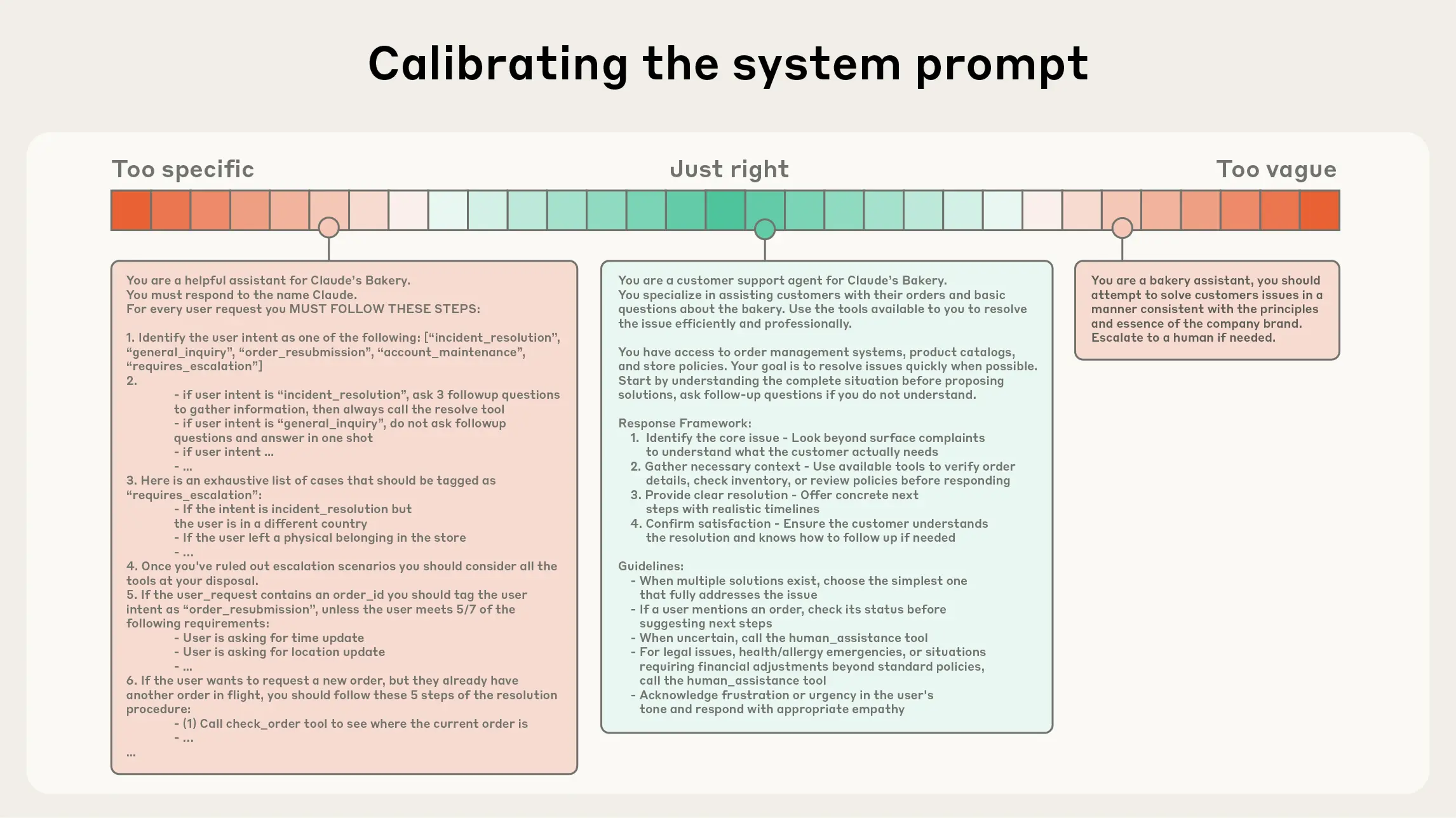
At one end of the spectrum, we see brittle if-else hardcoded prompts, and at the other end we see prompts that are overly general or falsely assume shared context.
Tip 1: Organize prompts into distinct sections
Anthropic recommends the following techniques.
- Separate sections when composing prompts, such as
<background_information>,<instructions>,## Tool guidance, and## Output description - Use technologies like XML tags or Markdown headers to delineate sections
Tip 2: Keep it minimal, but include all the essential details
- However you structure your system prompt, aim to provide the minimal set of information that fully describes the expected behavior.
(“Minimal” here does not mean “short.” You must provide sufficient information so the agent can perform as intended.)
- Start with the minimal prompt length and observe how the agent behaves, then iteratively add clear instructions and examples to improve precision and reliability.
Tip 3: Design tools to be efficient and clear
Tools are the core mechanism that let agents interact with their environment and bring new context in. Because tools serve as the contract between the agent and the information or action space, they must be designed for token efficiency and for inducing efficient agent behavior. Anthropic emphasizes the following principles for tool design:
- Clear, non-overlapping functions: design tools so their roles do not overlap and are intuitive for the LLM to understand.
- Robust, well-scoped purpose: like well-designed code, tools should be self-contained, resilient to errors, and have a clear intended use.
- Clarity of input parameters: avoid ambiguity and play to the model’s strengths.
Tip 4: Avoid bloated tool sets — keep it minimal
A common failure mode is a toolset that becomes too large. Functions overlap, and it becomes unclear which tool to use in which situation. If even a human engineer cannot confidently choose a tool, it will be difficult to expect better performance from an agent.
Tip 5: Use diverse, canonical examples — not a laundry list
Few-shot examples remain a very powerful best practice. But many teams try to stuff every edge case into the prompt, increasing complexity and confusion.
Anthropic recommends:
- Do not attempt to enumerate every rule
- Carefully curate representative and diverse canonical examples
- Help the agent internalize the expected behavior intuitively
- For an LLM, examples are “pictures worth a thousand words”
Tip 6: Keep your context informative, yet tight
Across all context components (system prompt, tools, examples, message history), aim to:
- Include enough information
- Yet keep it from becoming unnecessarily long
This makes it easier for the agent to dynamically retrieve or adjust context at runtime and still operate efficiently.
5. Context retrieval and agentic search
An agent is defined as an LLM autonomously using tools in a loop, and as models improve, agents can become more autonomous. The current trend is to use a just-in-time strategy that injects dynamic context at the right moment.
5.1 Just-in-time Approach: Lightweight Identifiers & Dynamic Context Retrieval
Agents built with a “just-in-time” approach maintain only lightweight identifiers like file paths, stored queries, and web links, and at execution time they use tools to dynamically load the necessary data into context. (Anthropic’s agentic coding solution, Claude Code, adopts this approach.)
5.2 Metadata Signals & Progressive Context Accumulation
Beyond storage efficiency, reference metadata such as folder structures, filenames, and timestamps serve as strong signals for how and when to use information. For example, even with the same name, tests/test_[utils.py](http://utils.py) differs in purpose from src/core_logic/test_[utils.py](http://utils.py), and the agent can infer this.
Allowing agents to independently explore and retrieve data enables progressive disclosure. Information gained from an initial pass influences subsequent decisions, and file size, names, and modification times provide hints. This way, the agent keeps only important information in working memory and uses memo strategies to fetch the rest when needed, avoiding distraction by irrelevant data and focusing on high-relevance information.
5.3 Limitations of runtime exploration and tool design
Runtime exploration is slower than loading pre-computed data. And to navigate information effectively, the agent needs appropriate tools and heuristics. Without them, the agent may waste context through poor tool use, inefficient exploration, or missing key information.
5.4 Trade-offs, design challenges of runtime exploration, and future directions
A hybrid strategy can be effective: preload some data for speed, and let the agent autonomously explore the rest as needed. For example, the Claude Code agent starts by loading CLAUDE.md into context, then uses commands like glob and grep to explore files when needed, avoiding stale indexing or complex syntax tree issues.
This hybrid approach is especially suitable for domains like law and finance where content changes less frequently. As models improve, designs will reduce human intervention and move toward autonomous agents that decide for themselves.
6. Context engineering for long-horizon tasks
For long-duration work that exceeds an LLM’s context limits, agents need separate strategies to maintain coherence and goals. To address context pollution, Anthropic uses compaction, structured note-taking, and multi-agent architectures.
Context Engineering Tip 1: Compaction
Compaction takes a conversation that is nearing the context window limit and summarizes it to create a new context window. This is the first method in context engineering to improve long-term coherence.
The key is deciding what to keep and what to discard. When writing compaction prompts, first maximize recall so the prompt captures all relevant information in the trace, then iteratively remove unnecessary content to improve precision.
Context Engineering Tip 2: Structured note-taking
Structured note-taking, or agentic memory, is the technique of continuously writing notes outside the context window so they can be re-injected later when needed.
This provides persistent memory with minimal overhead. As simple as creating a to-do list or maintaining a Notes.md file, this enables agents to track progress on complex tasks and maintain important context and dependencies.
Even after a context reset, the agent can read its notes and maintain context. This enables long-horizon strategies.
Context Engineering Tip 3: Sub-agent architectures
Sub-agent architectures offer another way to overcome context limits. Instead of one agent maintaining all state, specialized sub-agents each handle specific tasks and run independently with clean context windows. The main agent (orchestrator) coordinates the overall plan, while sub-agents execute detailed tasks and exploration.
This allows a clear separation of concerns. While sub-agents handle complex exploration, the main agent focuses on synthesizing and analyzing results. In Anthropic’s multi-agent research system, this pattern outperformed single-agent approaches on complex research tasks.
Depending on the task:
- Compaction suits workflows with long conversational flows
- Structured note-taking works well for iterative development and clear milestone tracking
- Sub-agent architectures suit complex research and analysis where parallel exploration provides benefits
7. Summary
To design agents and overcome limited context, remember:
Prompt engineering
- Organize prompts into distinct sections
- Keep it minimal, but include all the essential details
- Design tools to be efficient and clear
- Avoid bloated tool sets — keep it minimal
- Use diverse, canonical examples — not a laundry list
- Keep your context informative, yet tight
Context engineering
How do we maintain context well?
- Strategy 1: Compaction
- Method: Periodically compress and summarize conversation and work history, keeping only core goals, decisions, and unresolved items to form a new context window. Keep important evidence and citations as brief reference links or identifiers.
- Pros: Saves context window. Improves long-term coherence. Reduces unnecessary repetition and stabilizes reasoning.
- Cons: Poor compaction can lose important details. Risk of cumulative summarization bias.
- Best suited for: Long-running conversations and research, flows requiring periodic check-ins, and collaborative documents with many changes.
- Risk mitigation tips: Before summarizing, use a “key facts checklist” to prevent loss. Keep original identifiers for critical numbers, IDs, and file paths.
- Simple workflow example: Weekly snapshot → keep only decisions, evidence, and TODOs → archive the previous window via links.
- Strategy 2: Structured note-taking (structured notes, agentic memory)
- Method: Persist progress, reasons for decisions, TODOs, and evidence links as structured notes outside the context window, and re-inject only what’s needed just in time.
- Pros: Minimal overhead for persistent memory. Easy to recover after context resets. Easier to track dependencies and causal chains.
- Cons: Search and reinjection quality depend on note quality and structure. Without a synchronization strategy, duplication and stale information can mix in.
- Best suited for: Iterative development cycles, milestone-based projects, and domains where evidence tracking is important.
- Risk mitigation tips: Always include dates and versions in notes. Move stale items to an “Archive” section. Fix a section schema to reduce quality variance.
- Notes.md section schema example:
- Goals: Summary of this sprint’s goals
- Decisions: Decision, supporting links, and impact
- TODO: Priority, owner, and deadline
- Evidence: PR links, logs, and file paths
- Strategy 3: Sub-agent architecture (multi-agent)
- Method: The orchestrator maintains the overall goals and interface. Role-based sub-agents handle exploration, summarization, coding, and verification in parallel with independent context windows.
- Pros: Minimizes context pollution through separation of concerns. Improves speed via parallel exploration. Easier to isolate failures and swap components.
- Cons: Increases design complexity. Requires managing contracts across agents such as I/O schemas and quality criteria. Coordination failure can waste loops.
- Best suited for: Large-scale research, codebase analysis, and multi-stage data pipeline design where parallelism yields benefits.
- Risk mitigation tips: Codify I/O schemas, quality bars, and exit criteria as contracts. Set round limits and budgets to control exploration loops.
- Sample role set: Explorer, Reader, Synthesizer, Verifier, Orchestrator