Roboduck LLM Fuzzer Review, How the Theori Team Builds Effective AI Agents
How the Theori Team Makes Their LLM Fuzzer Effective

RoboDuck from Theori
0. Introduction
This post is a review of the LLM Fuzzer created by the Theori team (AIxCC). It has been reinterpreted from the perspective of “How to build an effective agent,” and there may be some minor inaccuracies, so please keep that in mind.
1. Background
- CRS (Cyber Reasoning System): A fully automated system that proceeds from binary analysis to vulnerability discovery to exploit generation to patching without human intervention.
- Interprocedural Value Analysis: A static analysis technique that traces the flow of variable values and constraints across function-call relationships. This enables detection not only of bugs confined to a single function, but also bugs arising from inter-function data flows, such as null pointer dereferences, array index errors, and overflows.
- PoV (Proof Of Vulnerability): The input, scenario, and procedure that concretely reproduces a software vulnerability (bug) to prove its validity.
- Focuses on concrete inputs/steps that reproduce the vulnerability itself. For example: specific input values, an HTTP request sequence, etc.
- Scaffolding: Supporting code or auxiliary structures needed to make the core functionality work reliably.
2. Approach
- Orchestrate all phases such as fuzzing and static analysis techniques around an LLM. Operates without human input (fully automated).
- Code patching: Use an LLM or an LLM Agent to author source code that fixes discovered bugs.
- CRS Architecture: https://github.com/theori-io/aixcc-afc-archive/blob/main/docs/crs-architecture.md
3. Bug Finding
- Run static analysis and fuzzing in tandem.
- For static analysis, use an existing tool (fbinfer), while two other LLMs approach the task with different methods.
3-1. Static Analysis with Infer
[Infer analysis tool]
- Rationale for choosing Infer: supports multiple languages and does not require defining project-specific rules for each repository.
- Performs interprocedural value analysis to detect null dereferences, out-of-bounds errors, overflows, and more.
[Issues while using Infer]
- Infer must be made to fully understand the source code. This requires intercepting the actual compilation to collect build information, not just reading raw source text.
- Implementation is easier for C but difficult for Java.
- When Infer cannot conclusively prove code safety, it emits a report. This can lead to an increase in false positives.
- There are cases where it fails to report genuinely vulnerable code. In particular, there are issues in its overflow checking routines.
As a result, the Infer tool yields an empirically measured 99.9% false-positive rate.
3-2. Static Analysis with LLMs
- Core concept: Have the LLM learn from code samples and find bugs.
- Because the codebase under analysis is large, complex agent-based approaches are impractical. Therefore, use a single LLM.
[Core methodology]
- In “single function” mode, the LLM analyzes exactly one function at a time with no additional context.
In “large code chunk” mode, multiple source files can be added, and related code is grouped in the same context to perform interprocedural analysis.
See detailed code at https://github.com/theori-io/aixcc-afc-archive/blob/main/crs/analysis/full.py
[Results]
- Found bugs that other existing techniques missed.
When provided with a diff, the task becomes easier. An LLM Agent receives the diff and focuses on bugs introduced by the changes. → Two agents are used in parallel. One prunes unrelated code based on in-compiler checks.
→ This approach significantly reduces false positives.
- Additional notes
- Theori CRS pipeline: bug detection → PoV generation → patch generation.
- After completing a patch, to verify that the patch does not introduce new bugs, the LLM Agent is shown only the pre- and post-patch diff to check for issues.
4. Fuzzing
[Baseline fuzzing strategy]
- Rather than building complex custom harnesses, reuse libFuzzer harnesses provided by projects, and match pre-collected suitable inputs (corpus) to each harness to maximize early fuzzing performance (coverage and crash discovery).
[Augmenting with a Fuzzer and an LLM Agent]
- For code paths the fuzzer cannot reach, use an LLM Agent to cover those areas and generate inputs.
- The LLM-based seed generator can discover new inputs even when the existing corpus has plateaued, enabling the fuzzer to achieve greater code coverage.
- When the agent attempts to create a PoV, inputs crafted in that process are also supplied to the fuzzer as new seeds.
- In some cases, the fuzzer, starting from the agent’s PoV as a seed, mutated it to trigger the same target more reliably or faster than the agent’s direct PoV execution.
[Handling fuzzer crashes and creating reports]
- Fuzzing can produce many crashes, requiring “triage” such as prioritization and deduplication.
- Fuzzing outputs crash dump files, which must be converted into a natural-language report.
- Therefore, proceed as follows:
- Discover numerous crashes
- Group by stack hash to deduplicate
- If a crash group is already patched, link it immediately or move it to the “post-patch revalidation” group
- Additional notes
- Stack hash: a normalized hash of the crashing call stack (e.g., FunctionA → FunctionB → crash site).
5. Bug Filtering
- Static analysis outputs contain many false positives. These must be filtered before patching or exploitation attempts.
[Solution 1 - Vulnerability Scoring]
Key idea: With a single LLM call, request the model to output just one token indicating whether the bug is ‘likely’ or ‘unlikely’ to be real.
- Instead of treating the result as a simple “likely” or “unlikely,” assign a log probability.
- Modern LLMs often use a Mixture-of-Experts (MoE) architecture, so different expert nodes may be selected at runtime, producing varying results. → Sample multiple times and average or otherwise stabilize to increase confidence.
- Example result: probability of being a bug = 0.8
[Agent-based analysis]
- To judge whether a generated report is accurate, use an LLM Agent with access to a source-browsing tool. When the report is deemed valid, it adds further details.
- The analysis cost is $0.5 per item, and there can be tens of thousands of reports. Analyze only the top 20% or up to an expected per-task budget to control costs.
6. PoV Generation
- Bugs that survive the fuzzing and bug-filtering stages are sent to the PoV Generator.
- This agent is distinct from the ones mentioned previously and is responsible for developing inputs that trigger the specified bug.
- It generates inputs via the two pipelines below.
6.1 Input Encoder
[Basic operation]
- A Python function that takes parameters and produces a binary blob consumable by the harness.
- Parameters are chosen by the LLM Agent that authors the script.
- Test the encoder in isolation.
- Goal: Guarantee that the encoder produces exactly the intended bytes.
[Centralization and caching]
- All PoV generators targeting the same harness reuse a shared encoder.
Implement and test the encoder thoroughly once, and cache its outputs.
→ Reduces debugging overhead and improves efficiency across multiple PoV attempts for the same harness.
6.2 PoV Producer
[Role of the PoV Producer]
- Does not directly access source code; instead queries a “source questions” agent for necessary information.
- Does not perform debugging directly; instead tests via a Debug Agent.
- Can execute its own PoV and use the prebuilt Input Encoder.
[Parallel execution across multiple models]
- Run Claude Sonnet 3.5 and 4, and OpenAI o3 in parallel.
- This incurs higher costs but yields results faster.
- On success:
- If any of the three models succeeds in creating a PoV and reproducing a crash, immediately stop the other models.
7. Patch Generation
Patch generator and diff alignment capability
- Bugs are sent simultaneously to the PoV Generator and the Patch Generator. (An optimization to reduce latency at increased cost.)
- Patch Generator Agent characteristics:
- Validates the agent-created diff using a sequence alignment function to determine exactly which line the patch should apply to and to correct minor mismatches.
- Additional notes
- Examples of minor mismatches: function name typos, line-number differences, etc.
(It may look like a small feature to apply diffs, but substantial research was required to ensure application accuracy.)
Automated patch validation and retries
- When a vulnerability is triggered by a PoV or fuzzing input, the related patch is automatically applied and verified to ensure the discovered vulnerability is actually fixed.
- If the patch is incorrect, the patching process restarts.
- Test cases that caused prior failures are recorded.
- When a new patch is produced, those failing cases are re-validated.
8. Fully Automated Pipeline of Theori CRS & Summary
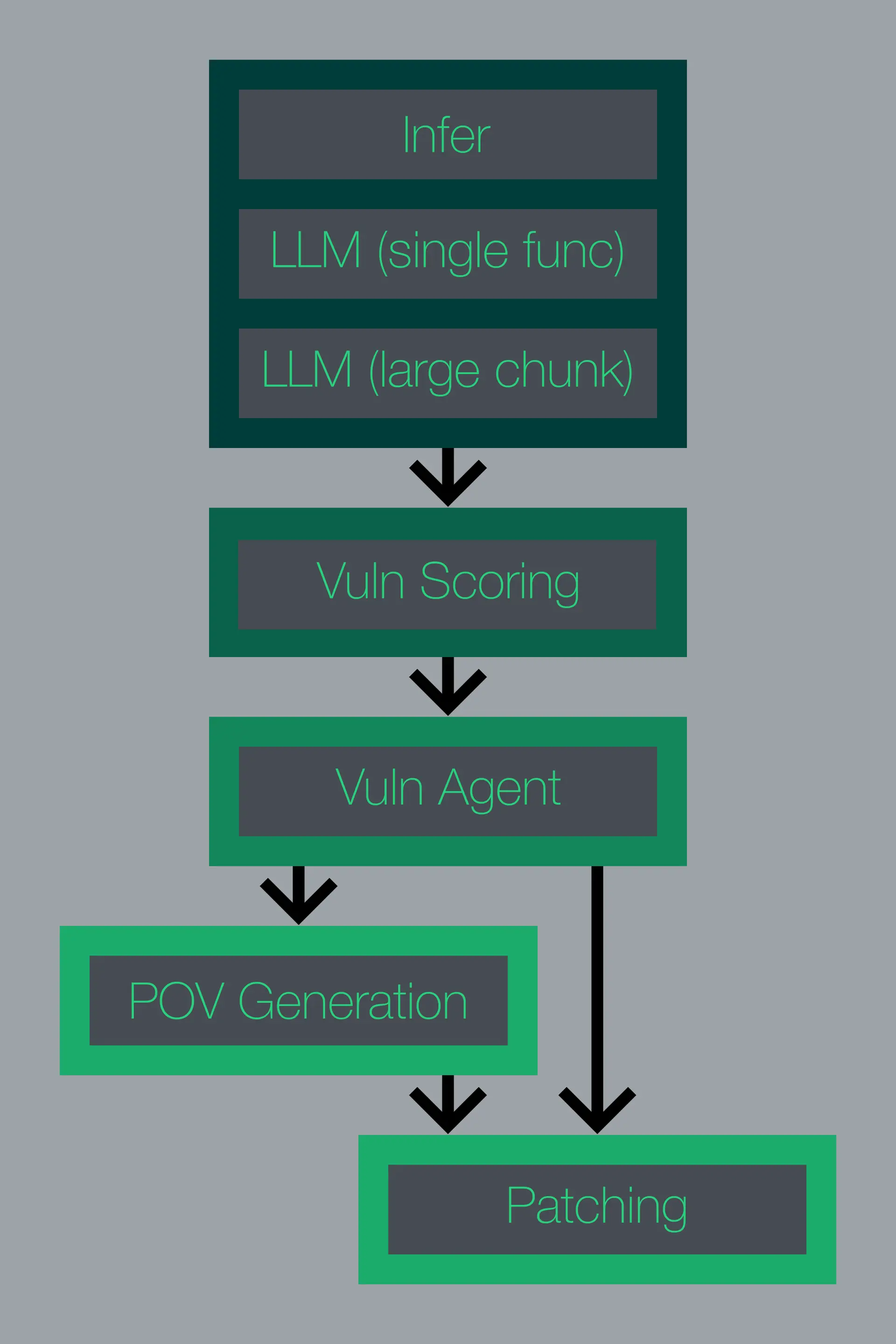
- Bug Finding
- Identify candidate vulnerabilities via static analysis (Infer) plus LLM analysis (function-level and large-code-chunk) plus lightweight fuzzing.
- Vulnerability Scoring
- Convert the LLM’s “likely / unlikely” signal into a score and prioritize vulnerabilities with higher likelihood of being real.
- Vuln Agent
- Performs deeper analysis on high-scoring vulnerabilities and hands off to the next stages (PoV, Patch).
- PoV Generation
- Normalize inputs with an Input Encoder, then have an LLM generate a PoV that actually triggers the bug.
- Feed seeds to the fuzzer as well to achieve synergy.
- Patch Generation
- Generate patches automatically in parallel.
- The LLM creates diffs, and sequence alignment corrects the application location.
9. Operational Foundations: Orchestration, Source Browsing, Builds, and Docker Running
- The most effort in building the CRS went into the scaffolding and glue that keep the logic running correctly.
- The issues encountered were mostly in the supporting code, not fundamental limitations of the approach.
9.1 Orchestration and Scheduling
- Theori CRS manages all tasks within a single asynchronous Python process that includes thousands of concurrent workers.
- Job Scheduling manages access to deliberately limited resources such as LLM APIs and Docker.
9.2 Source Browsing
- Adopt a dedicated-tool approach via an in-house Agent’s Source Browsing.
- Tooling list: TreeSitter, GTags, Joern, clang-ast, and others.
9.3 Builds
- CRS requires building the target project for almost every task.
- Exception: LLM-based static analysis, which only reads source code and thus does not require builds.
- Automating builds is very difficult.
- Complex interdependencies and environmental issues abound.
- However, thanks to oss-fuzz packaging that enables automatic builds for many open-source projects, it is feasible.
- Multiple build types are required.
- Debug builds (with debug symbols), coverage builds (to inspect executed code paths)
- Static-analysis-instrumented builds (for analysis tools)
- Sanitizer builds (ASan, UBSan, etc., for runtime error detection)
- Patch-application builds (to verify new patches function correctly)
- Build strategy: eager vs. lazy
- Eager builds: perform in advance to reduce latency
- Lazy builds: perform on demand to conserve resources
- Caching: reuse results to avoid repeating identical builds
9.4 Docker Running
- Heavy tasks such as builds and fuzzing run on remote Docker hosts, separate from the CRS core.
- Instead of dynamic scaling via Kubernetes, use statically allocated Docker hosts to simplify management and improve cost predictability.
- Designed for stable operation without dedicated SRE monitoring.
- Drawback: remote execution requires exchanging containers and data. In the final submission, simple tar-file transfers were used.