How a Cybersecurity Researcher Prepared for the Kakao AI Top 100 (Part 1)
A security researcher shares the strategy and practical insights behind a fully automated agent system that reached the Kakao AI Top 100 finals.

1. TL;DR
“How should we design a system that can efficiently solve general-purpose problems?”, “How should we prepare for Kakao AI Top 100?”
These were the questions I wrestled with before preparing for the competition and they’re the kinds of questions anyone who wants to solve broad, real-world problems with LLMs will likely face at some point.
In this post, I’m sharing the tools I personally designed and used as a finalist, and releasing them as open source, along with the fundamentals you should check before designing an agent system and practical, no-filter ideas and know-how for tackling general-purpose problems. This series has two parts. Part 1 summarizes the overall flow of Kakao AI Top 100 and hands-on strategies that help with preparation. Part 2 dives deep into the architecture and techniques behind the agent I built and used in the competition.
2. Introduction
2.1 What is Kakao AI Top 100, and how does it work?
It’s a large-scale competition hosted by Kakao. For more information, KaKao is one of the biggest coporation in South Korea. There are plenty of generic write-ups out there, so I’ll focus on what you actually need:
- Problem types: Not limited to a single domain—covers a wide range of areas. (You can check past problems here.)
- Number of problems & time: As of 2026, preliminaries are 5 problems / 2 hours, finals are 5 problems / 3 hours.
“Wide range of areas” may still feel vague, so here are a few examples. The tasks vary from organizing massive sets of files to extracting data from multimedia materials. 

2.2 Can’t we solve it by using existing models or tools as-is?
No. Using models or tools “as-is” isn’t enough.
The problems are complex enough that simply using Claude, Gemini, or GPT won’t cut it. Even if you use tools that make LLMs “smarter,” like Claude Code + everything-claude-code or oh-my-opencode, you’ll still run into issues:
- Claude Code + everything-claude-code: (Except for a few simple tasks) hard to expect top scores.
- oh-my-opencode: doesn’t finish within the time limit + a disaster where one problem can cost $60+.
In short, existing tools were not efficient at all in terms of output quality and cost—so I designed my own system.
2.3 From what perspective did I approach and prepare for the competition?
Hi, I’m Eric Kim, a cybersecurity researcher (offensive security). I’m especially interested in building LLM-based tools for automating vulnerability research. A lot of my work boils down to: “How can we make LLMs read and process code well?”. And because I’m the kind of person who thinks “I wish this could be handled end-to-end with minimal human intervention,” I had two core questions:
- Do methodologies already used in software/security generalize to solving broad, general-purpose problems?
- Can we build a fully automated system that solves competition problems without human input?
To answer these, I prepared by adapting methodologies from my domain and designing a system aimed at full automation.
3. Designing a Competition Strategy
I started by designing the strategy first, then built a system to match it. The strategy was:
3.1 Define the system’s goal and philosophy
LLM performance has already reached a point where “Can it solve the problem at all?” is no longer the core issue. Given a hard problem, an LLM will usually produce something.
The real questions are:
- Does it solve the problem correctly?
- Does it solve it efficiently at low cost?
- Does it produce consistent answers every time?
Based on these, I set the goal: fully automate problem solving to achieve high scores efficiently and at low cost. I also followed a “Simple is the Best” philosophy, keep the structure as simple as possible while extracting maximum efficiency.
3.2 Classify problem types that can be fully automated
I split problems into two categories: “problems that rely on multimedia materials” vs “everything else.” Multimedia problems usually include video or audio files, and you won’t get high scores if you try to fully automate them with an LLM.
These are typically Human-in-the-loop (HITL) tasks, so I excluded them from the full-automation target when designing the system. On the other hand, for text/code/PDF-type tasks where LLMs tend to show strong understanding. I chose them as the primary target for full automation.
3.3 The strategy I adopted
- Classify HITL (Human-in-the-loop) problems
- For non-HITL problems: delegate the solving entirely to the fully automated system
- For HITL problems: solve interactively with the LLM
In prelims you have 2 hours; in finals, 3 hours; typically 5–9 problems. Given the time pressure, it’s unrealistic to solve every problem in a tight loop with the LLM. So I solved only the HITL problems directly and let the automated system solve the rest in parallel.
4. Pre-System Design Checklist (a.k.a. Competition Prep Checklist)
As shown in the examples, this competition involves problems far more general-purpose than you might expect. Using existing models or bolting on tools is not enough to score well. So I prepared my own strategy by starting from the most fundamental questions. These are essential questions not only for competition prep but also for anyone trying to solve broad problems more efficiently.
4.1 Which model should handle which type of problem?
Everyone knows different models are good at different tasks. The first step was to figure out which model excels at what. During my preparation period, I observed:
- Claude: good for orchestration and planning
- Gemini: good for multimedia tasks like image recognition and video-related work
- GPT: good for writing code
Based on that, I delegated most problems to Claude & GPT, and assigned only multimedia-heavy problems to Gemini.
4.2 What are the context limits and costs of each model?
For complex problems, “How much context can it handle?” becomes critical, and cost matters too. During the preparation period, the rough picture was:
- Claude: ~1M context. Claude Pro $20/month
- But there was a bug during the contest where tokens could be consumed excessively (reference)
- Gemini: ~1M context. Google AI Pro $19.99/month
- GPT: ~1M context. ChatGPT Plus $20/month
So context capacity and cost weren’t hugely different.
4.3 Given real-world constraints, which models should we use?
If you have unlimited budget, you could use everything—but realistically, you have to optimize cost. I chose Claude and GPT, for these reasons:
- Claude’s planning ability is significantly stronger than other models, which helps on complex problems.
- I already had an existing Claude $220 subscription plan and a GPT plan for research, so I reused them.
- For problems involving multimedia, Gemini performs much better, so I added it.
Based on these answers, I proceeded with the system design.
4.4 (Key) Did the system actually solve the original problems?
Yes. The automated system definitively addressed the issues I had with baseline approaches. 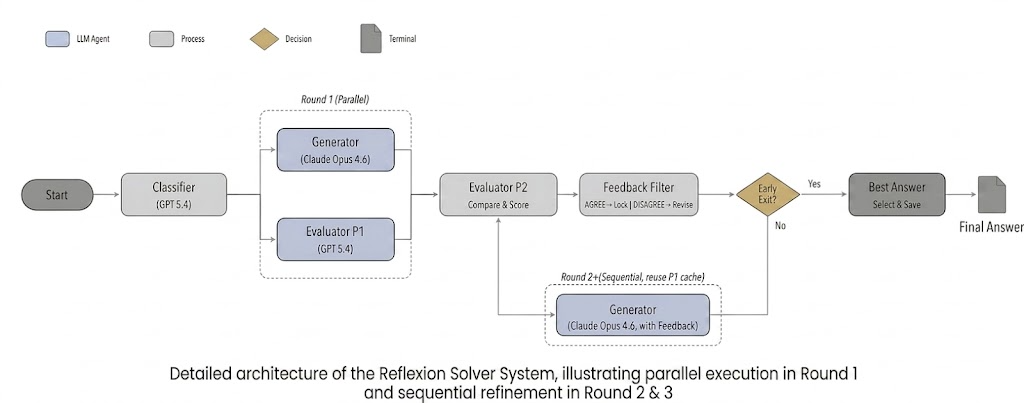 When I tested my system on tasks that were not HITL (Human-in-the-Loop) types, the results were successful, as shown below.
When I tested my system on tasks that were not HITL (Human-in-the-Loop) types, the results were successful, as shown below.
| Problem Name | Max Score | Vanilla LLM Score (A) | Developed System Score (B) | Improvement (B-A) | System Solving Time |
|---|---|---|---|---|---|
| 2026 CSAT: The Dialogue of That Day | 55 | 20 | 55 | +35 | 54 min |
| Find the Free Rider | 75 | 35 | 45 | +10 | 45 min |
| Finding Website Bugs | 60 | 50 | 60 | +10 | 51 min |
| Drafting Handover Documents | 75 | 45 | 53 | +8 | 47 min |
| Discover Innovators in the News | 80 | 20 | 60 | +40 | 64 min |
| Total Score | 345 | 170 | 273 | - | - |
| Score Percentage | - | Approx. 49% | Approx. 80% | - | - |
It also addressed the key questions as follows:
Q1. Does it solve problems correctly? And does it produce consistent answers?
It solves them well and produces consistent outputs. The Reflexion structure I adopted makes this efficient: a Generator attempts the solution first, and an Evaluator critiques it and provides feedback. This gives a total of three rounds of checking. Even if the LLM starts in the wrong direction, the system nudges it toward a better strategy, leading to correct solutions and more consistent answers.
Q2. Does it solve problems efficiently at low cost?
It does. To be concrete, because my system solves and reviews a problem three times, I also evaluated the baseline by forcing it to “solve + review” three times.
[ Efficiency ]
LLMs have well-known limitations: First, they have finite context, and beyond that capacity, performance and efficiency can degrade sharply (source). Second, the older the input within the context window, the lower the accuracy tends to be (source). Third, when asked to evaluate their own outputs, LLMs tend to be overly positive (source). Fourth, even across different model versions, if the reasoning chain becomes long, they often converge to similar styles of reasoning (e.g., Sonnet vs Opus converging similarly over long runs).
KAKAO provides data far exceeding the total context capacity of LLMs. So context rot is inevitable, and handling it well is essential to score highly.
My approach was:
- For each dataset, write a “core summary” memo to the file system and re-reference those memos as needed.
- This mitigates the “older context is less accurate” effect and reduces the efficiency cliff when you exceed context capacity.
- Use different models for Generator vs Evaluator.
- The same model tends to follow similar reasoning paths and produce similar low-quality outputs, so separating roles can improve direction and output quality.
- Having a different model evaluate the output avoids the “self-praise” tendency and improves quality.
With this, you can score higher than a plain LLM.
[ Cost ]
Because my system runs three solve/review rounds, I compared it against a baseline that also does three rounds. The system significantly reduced cost while improving scores.
The cost reduction comes from: First, the “summarize and re-reference” strategy avoids re-reading all the data to select an answer. Second, when reviewing, a plain LLM often has to start over from scratch, but the system can review based on already-produced work. A concrete example: running a certain problem with oh-my-opencode cost $68 per turn—roughly $204 over three turns.
The system avoided this kind of failure mode and achieved higher scores at lower cost.
5. Prelims & Finals Results + Takeaways
5.1 Prelims results
In the 2026 Kakao AI Top 100 Campus prelims, five problems were given: “2026 CSAT,” “Digital Art Appraiser,” “Freerider,” “Find a Website Bug,” and “1906 Today Hanseong.”
I delegated “2026 CSAT,” “Freerider,” and “Find a Website Bug” to my fully automated system, and solved the other two by interacting directly with the LLM. As a result, I advanced to the finals (Later, after checking the archived problems site again, it turned out two were perfect scores and the remaining one was a solid score.)
5.2 Finals results
I didn’t win an award, but I did gain insights that should help people preparing for next year. Here’s a comparison between prior years’ problems and the 2026 finals.
Characteristics of pre-2026 problems
- Mostly problems that an LLM could solve “somehow”
- No tasks designed to force extreme token consumption
- Even with multimedia, there were no tasks requiring you to directly produce videos or PPTs
Characteristics of 2026 finals problems
- New task type: listen to audio files and solve questions
- Tasks designed to cause extreme token consumption, preventing other work during the contest
- Most problems involved multimedia
My system aimed at full automation for non-multimedia tasks. However, in the finals, most problems were multimedia-heavy (including audio-listening tasks), and even the few tasks that could fit full automation were designed to consume an excessive number of tokens. (This was explicitly stated by the problem setter.) So I unfortunately failed to win an award.
6. Conclusion: Breaking Through Model Limits with System Design
Many people ask, “Which LLM is the smartest?”
But after preparing for Kakao AI Top 100, I reached a different conclusion: What matters is not the model’s intelligence itself, but how you put that intelligence into a pipeline and design a system that extracts the best possible results. As an offensive security researcher, my passion for automation was a double-edged sword in this contest. But there were clear gains.
6.1 Three takeaways from a researcher’s perspective
- Domain extensibility: The “reasoning–verification–feedback” methodology used in vulnerability research proved strong efficiency (cost and accuracy) even for general-purpose problem solving.
- Overcoming context limitations: Mitigating “context rot” with a file-system memo strategy also works for general-purpose tasks.
- Making “handle it end-to-end” real: A fully automated system with minimal human intervention cleared the practical hurdle of passing prelims—showing that the methodology I study in security can generalize.
Of course, the “multimedia-heavy problems” and “intentional token consumption traps” in the 2026 finals are the next challenges for the system. But failure is simply the best dataset for building a more refined system.
6.2 What to keep in mind when preparing
No one knows what problem types will appear next year. But based on my experience, I expect:
- More encouragement to solve via diverse media
- Even stronger anti-LLM strategies designed to consume more tokens
7. Closing
I hope this post sparked ideas for designing your own agent. This was just the retrospective—the real technical analysis starts now. In Part 2, I’ll break down my agent’s Reflexion architecture and prompt engineering techniques, and walk through the open-source code piece by piece.
See you in Part 2, where the code does the talking. Thanks.